
The JVM utilizes its own memory model, and upon launch, the system allocates memory for the process, which is then shared among various memory areas:
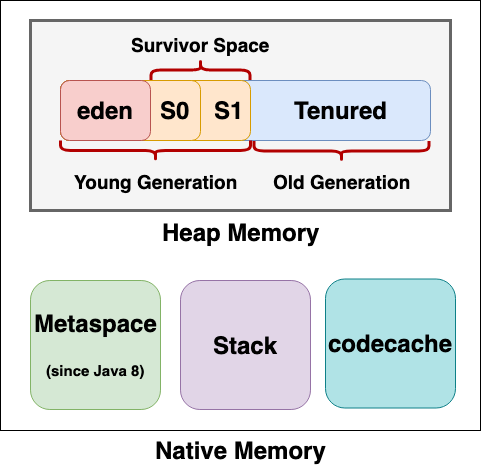
- Heap Memory: Java objects reside in one of the heap areas.
- Metaspace: Since Java 8, it has replaced the older PermGen memory space, offering a more flexible and reliable memory usage.
- Stack Memory: A JVM stack is created for each thread. It stores local variables, partial results, performs dynamic linking, and manages the return values from methods and dispatches exceptions.
- Codecache: This area is predominantly used by the just-in-time (JIT) compiler to store bytecode compiled into native code.
Heap Memory
Heap memory is divided into two generations: young (nursery) and old. It is where object data is stored and managed by the Garbage Collector.
Garbage collection is the process of inspecting heap memory to clean up unused objects. A used object is one that is referenced, implying that somewhere in your program, there is something pointing to that object. In contrast to languages like C, where this is a manual process, Java handles it automatically.
Young Generation
When the young generation becomes full, a minor garbage collection occurs, triggering a “Stop the World” event. Surviving objects are moved to the old generation.
“Stop the World”: All application threads are halted until a particular operation completes.
Within the Young Generation, three areas exist: Eden, Survivor Space 0, and Survivor Space 1.
Old Generation
The Old Generation stores long-surviving objects. To classify an object as a candidate for movement from the young to the old generation, a threshold is set. Eventually, the old generation undergoes a major garbage collection, a “Stop the World” event, which is slower due to involving live objects. Thus, these events should be minimized.
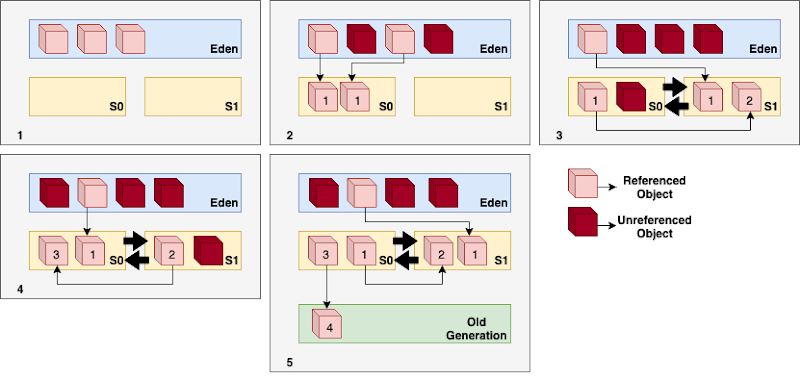
Generational Garbage Collection Process
The Garbage Collector is an automatic process responsible for identifying and deleting unused objects through the following steps:
- New objects are placed in the Eden and Survivor spaces, which start empty.
- When Eden becomes full, a minor garbage collection is triggered. Referenced objects move to the first survivor space (S0), and unreferenced objects are removed.
- The next time Eden fills up, a similar process occurs, but this time, referenced objects move to the second survivor space (S1), and those from S0 also move, incrementing their age. Unreferenced objects in S0 are removed.
- During the subsequent minor GC, the same process repeats, with survivor spaces switching. Referenced objects move to S0, survivors age, and unreferenced objects from Eden and S1 are removed.
- Objects reaching a certain age are promoted from the young to the old generation.
- Steps 1-5 repeat until a major GC is performed on the old generation, cleaning up and compacting the space.
Garbage Collector Selection
When no Garbage Collector is selected via the command-line interface (e.g., -XX:+UseSerialGC), the JVM chooses a GC based on the platform, heap size, and runtime compiler. This selection process is known as Ergonomics.
HotSpot Garbage Collection Types
- Young Generation Collection
- Serial (S GC): A stop-the-world collector that uses a single thread for garbage collection, freezing all threads during the process.
- Parallel Scavenge: A stop-the-world, copying collector using multiple GC threads.
- ParNew (P GC): A stop-the-world collector using multiple threads, freezing all threads during garbage collection. It has enhancements making it usable with CMS.
- Old Generation Collection
- Serial Old: A stop-the-world, mark-sweep-compact collector using a single GC thread.
- CMS (Concurrent Mark Sweep, CMS GC): Mostly concurrent, low-pause collector using multiple threads, freezing threads only during marking in the tenured generation space. It uses more CPU to improve throughput.
- Parallel Old: A compacting collector using multiple GC threads.
-
G1 (G1 GC): The Garbage First collector for large heaps, providing reliable short GC pauses. It uses regions to simplify collection, avoiding fragmentation issues. G1 offers more predictable garbage collection pauses and allows users to specify desired pause targets.
- The Z Garbage Collector (ZGC): Designed for low pause times on large heaps using colored pointers and load barriers.
To check the default GC on your machine, use:
java -XX:+PrintCommandLineFlags -version
Adjusting parameters is possible for a parallel GC:
- Maximum Pause Time Goal (
-XX:MaxGCPauseMillis=<milliseconds>): Adjusts heap size and other GC parameters to minimize pause time. This may increase GC frequency and reduce application throughput. - Throughput Goal (
-XX:GCTimeRatio=<milliseconds>): A ratio affecting both young and old generation time. It adjusts generation sizes to achieve the desired pause targets.
Tuning Heap Memory
System performance heavily depends on the available Java heap size. Follow these rules:
- Heap size < Available Physical RAM.
- Young Generation Size < Total Heap Size/2.
- Use the same values for minimum and maximum heap size to prevent wasting resources on constant heap resizing.
Options:
| Description | Option |
|---|---|
| Initial java heap size | -Xms |
| Maximum Heap Size | -Xmx |
| Initial and maximum size of the young generation | -Xmn |
Oracle advises against choosing a maximum heap size unless needed, recommending a throughput goal instead.
Metaspace
Metaspace is memory allocated for metadata. In JDK 8, it replaced the permanent generation. Class metadata, stored in native memory, has an unlimited default allocation, but you can set an upper limit with MaxMetaspaceSize. GC runs on metaspace when nearing full capacity. Includes:
- Class Metadata: Information about classes and interfaces, including the class name, methods, fields, and annotations.
- Internal JVM Representations: It includes the resolution state (linkage to other classes/interfaces, fields, methods, and constants), interpretation state (quick access resources for resolved references and basic profile counters), and compilation state (code entry addresses, linking stubs, and sophisticated profile counters).
Java Class Metadata
Java Class Metadata represents the JVM’s internal model of bytecode. The JVM creates this model, discarding the bytecode for complexity reasons. It includes resolution, interpretation, and compilation states, crucial for runtime modeling, interpretation, JIT, reflection, and JVM Tool Interface interactions.
Stack Memory
Java Stack memory is used for static memory allocation and during the execution of threads, stores short-lived method-specific values and references to objects in the heap. The memory follows a last-in-first-out (LIFO) access pattern, with size depending on the OS and being relatively small compared to Heap memory. It persists as long as the method is active, throwing a java.lang.StackOverflowException when full.
Code Cache
Code Cache is where the JVM stores native code compiled by the Just-In-Time (JIT) compiler. It uses native memory and is managed by the Code Cache Sweeper.
Code Cache Tuning
Tweak Code Cache consumption using JVM options:
| Option | Default | Description |
|---|---|---|
InitialCodeCacheSize | 160K (varies) | Initial code cache size (in bytes) |
ReservedCodeCacheSize | 32M/48M | Reserved code cache size (in bytes), the maximum code cache size |
CodeCacheExpansionSize | 32K/64K | Code cache expansion size (in bytes) |
UseCodeCacheFlushing | false | Attempt to sweep the code cache before shutting off the compiler |
CodeCacheMinimumFreeSpace | 500K | When less than the specified space remains, stop compiling. This space is reserved for non-compiled methods, e.g., native adapters |
PrintCodeCache | false | Print the code cache memory usage when exiting |
Restrictions on code cache benefit when much code is stored during startup, with little needed afterward. Code cache flushing will likely be triggered, making room for the necessary code during runtime.