
- Data structures
- Java Collection Interfaces
- Collection Interface
- List Interface
- Set Interface
- Queue Interface
- Map Interface
The Java Collections library provides a set of interfaces and implementations in the package java.util to satisfy most of the data structures needs.
A collection represents a group of objects or elements that can be ordered, unordered, with duplicates or without duplicates depending on the implementation. In the following sections we will cover the specific sub-interfaces like Set and List.
Data structures
There is no silver bullet when choosing an implementation, you have to make a tradeoff based on the operations used most frequently in your application.
Arrays
Arrays are the most used data structure and are implemented directly in hardware. They allow random access memory which means they are very fast for accessing elements by index and for iterating over them, but slower for iterations and deletions because it might require adjusting the position of other elements.
Some Java Collection implementations like ArrayList or EnumSet use arrays. They are also used as a mechanism to create hash tables.
Hash Tables
Hashing is a technique used to identify an object from a group of similar objects and a hash table is a data structure which stores data in an associative manner.
A hash table contains key associated to values, where the value is added to a bucket (linked-list) and the key is a unique index. This means insertion, removal and search operations are very fast, however they do not provide support for accessing elements by position. How does it work?
- The key is converted into an integer by using a hash function.
- The key-value pair is stored in the hash table where it can be quickly searched or removed using the hashed key. Two keys may hash to the same slot. We call this situation collision. One way to minimize collisions is by choosing good hash functions (use random values). When a collision happens the resolution technique is called chaining. In chaining, we put all the elements with same hash into the same liked list.
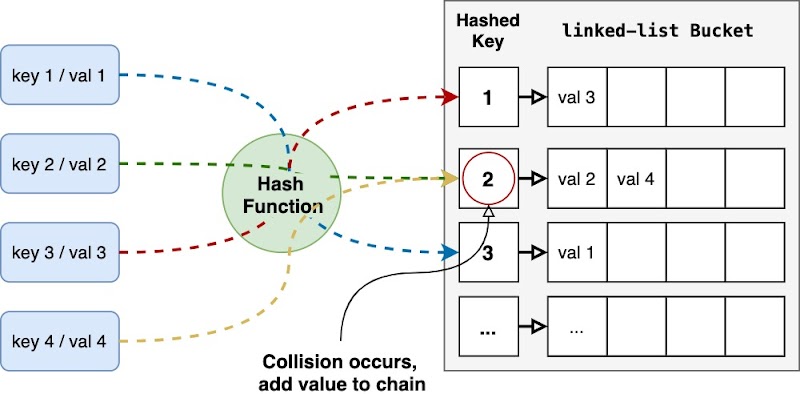
Hash tables can be found in HashSet, LinkedHashSet, HashMap or LinkedHashMap.
Trees
The elements in a tree structure are organized by content, and they are stored and retrieved in sorted order. They perform very well for insertion, deletions and searching operations.
Trees should be chosen over arrays or hash tables when you want to retrieve elements in sorted order.
Not all trees has the same performance benefits. An unbalanced tree (most or all the nodes are on one side) can give much worse performance (similar to linked list).
You can find trees structures on TreeSet or TreeMap.
Linked Lists
Linked lists consists of chains of linked nodes. Each node contains a reference to the value and a reference to the next node in the list.
In Doubly Linked List implementation, nodes also contain a reference to the previous node in the list.
Access to elements is slower than in arrays, because you have to go through references from the head node. However, insertion and removal can be performed in constant time by rearranging the node references.
They are used for the implementations LinkedList, ConcurrentLinkedQueue or LinkedBlockingQueue.
Java Collection Interfaces

Collection: contains common methods used by all its implementations. There is no direct implementation of this interface.List: is a collection which allows duplicates and order of insertion is preserved by its implementations.Set: is a collection without duplicates in which the implementations do not preserve the order of insertion.SortedSet: automatically sorts its elements.NavigableSet: is an extension of theSortedSetinterface with additional methods for easy navigation of the elements.Queue: provides first in, first out (FIFO) queue operations for add , poll , and so on.BlockingQueue: extendsQueueand supports concurrent access.Deque: inherits fromQueueand allows elements to be added or removed at both head and tail.BlockingDeque: extendsBlockingQueueandDequeand supports concurrent access.
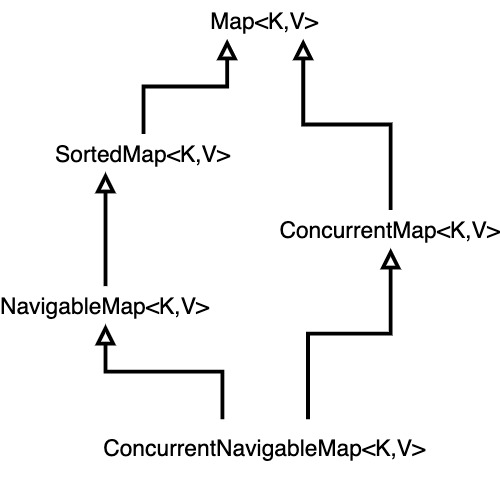
Map: is a collection to store key-value associations.SortedMap: returns its values in ascending key order.NavigableMap: is an extension of theSortedMapinterface with additional methods for easy navigation of the elements.ConcurrentMap: provides support for concurrent access.ConcurrentNavigablemap: extendsNavigableMapandConcurrentMap.
Classes implementing the Iterable interface can be iterated via the Java for-each loop.
The Java Collection interface inherits from Iterable, so any set, list or queue can take advantage of foreach.
e.g.
Set<Integer> integers = Set.of(2, 3, 5, 1);
for (Integer integer : integers) {}
the previous code generates:
Set<Integer> integers = Set.of(2, 3, 5, 1);
Iterator var2 = integers.iterator();
while(var2.hasNext()) {
Integer integer = (Integer)var2.next();
}
As you can see it is simply using a while loop under the hood.
Arrays can also use the foreach syntax, however the code generated is a traditional for loop
int[]integersArray = new int[]{1, 2, 3};
for (int integer : integersArray) {}
the previous code generates:
int[] integersArray = new int[]{1, 2, 3};
int[] var2 = integersArray;
int var3 = integersArray.length;
for(int var4 = 0; var4 < var3; ++var4) {
int var10000 = var2[var4];
}
Collection Interface
There are not concrete implementations of Collection and provides methods in four groups: adding (add, addAll), removing (remove, clear, removeAll, retailAll), querying (contains, containsAll, isEmpty, size) and transforming collection’s content for further processing (iterator, toArray). Therefore, it only provides functionality common to the different concrete implementations.
List Interface
A List is a collection which can contain duplicates. In addition to the Collection operations, this interface also provides some other methods given an index: add, addAll, get, remove, set; retrieve the index given an object: indexOf, lastIndexOf; retrieve a range of the list given two indexes: subList.
There are 3 concrete implementations of the List interface.

The time complexity of the operations is calculated with the Big O notation.
| name | get | add | contains | next | remove(0) | iterator.remove |
|---|---|---|---|---|---|---|
ArrayList | O(1) | O(1) | O(n) | O(1) | O(n) | O(n) |
LinkedList | O(n) | O(1) | O(n) | O(1) | O(1) | O(1) |
CopyOnWrite-ArrayList | O(1) | O(n) | O(n) | O(1) | O(n) | O(n) |
ArrayList
An ArrayList uses an array structure under the hood, but with the advantage of providing auto-resizing. When the ArrayList reach the size capacity, an additional element will trigger a resize operation which involves copying the all the elements into a new array with a larger capacity.
This structure performs very good for setting and search operations by index. The downside of the ArrayList is in inserting and removing elements, because it requires adjusting the position of other elements.
LinkedList
The LinkedList implementation performs better than a ArrayList for insertion and removal operations, since it only needs to rearrange the nodes. It is not recommended for random access, since it requires to iterate through all the elements.
CopyOnWriteArrayList
CopyOnWriteArrayList is an ArrayList that provides thread safety. To achieve thread safety it treats the collection as immutable, so a new copy is crate whenever any changes are made to the collection.
Vector
The Vector implementation uses a dynamic array, so it’s very similar to ArrayList, however, Vector is synchronized and contains additional methods.
Stack
The Stack class uses a last-in-first-out (LIFO) strategy and implements the Vector class. A stack structure is similar to a pile of papers, new elements are added on the top, and when you pull an element it comes off the top.
Set Interface
A set is a collection of items without duplicates in which the implementations do not preserve the order of insertion.
The Set is implemented by 6 concrete classes.

The time complexity of the operations is calculated with the Big O notation.
| name | add | contains | next | notes |
|---|---|---|---|---|
HashSet | O(1) | O(1) | O(h/n) | h is the table capacity |
LinkedHashSet | O(1) | O(1) | O(1) | |
CopyOnWriteArraySet | O(n) | O(n) | O(1) | |
EnumSet | O(1) | O(1) | O(1) | |
TreeSet | O(log n) | O(log n) | O(log n) | |
ConcurrentSkipListSet | O(log n) | O(log n) | O(1) |
Source: Java Generics and Collections - Maurice Naftalin and Philip Wadler - O’Reilly
HashSet
HashSet implements the Set interface and under the hood uses a hash table which is actually a HashMap instance. As described before hash tables expect a key-value pair, however in a HashSet you are only allowed to pass one parameter. The value you insert in a HashSet is inserted as the key, whereas the value associated to the key is a dummy object created automatically. Therefore, all the values in the key-value pair will be the same.
Objects you add in a HashSet are not guaranteed to be inserted in same order, instead they are inserted based on their hash code.
This data structure is not synchronized, not thread-safe, and its iterators are fail-fast.
Fail-fast iterators immediately throw
ConcurrentModificationExceptionif a collection is modified while iterating over it.
LinkedHashSet
This implementation inherits from HashSet and has the same properties (unsynchronized, not thread-safe and fail-fast iterator). You can use this class instead of a HashSet when you want to keep the order of insertion.
If the efficiency of iteration is important, you might consider this implementation instead of HashSet, since it is using a linked list and this means it performs in constant time.
CopyOnWriteArraySet
CopyOnWriteArraySet is an implementation of Set and a wrapper of CopyOnWriteArrayList, so it is using an array under the hood.
The main advantage of this class is the guarantee of thread safety.
As you can image this implementation is not very good for insertion and search operations, however it performs better than HashSet for iterations, since it’s using an array.
EnumSet
All the elements in an enumSet must come from an enum type. This implementation is very performance since the number of possible elements is fixed and a unique index can be assigned to each element.
Like most Set implementations, EnumSet is not synchronized.
TreeSet
A TreeSet uses a tree data structure as you can guess from the name. They are very good for insertion, removal and search operations, and they keep the elements in sorted order.
This data structure is not synchronized, not thread-safe, and its iterators are fail-fast.
ConcurrentSkipListSet
A skip list is made of multiple linked list layers, so that we can skip some nodes. These layers are created by choosing a random subset of elements given a probability, so the number of elements on above layers will decrease continuously.
The performance of this class is similar to a TreeSet and thread safety is the only advantage over TreeSet.
Queue Interface
The Queue interface provides some specific methods: poll, element, removed, peek and offer.

The time complexity of the operations is calculated with the Big O notation.
| name | offer | peek | poll | size |
|---|---|---|---|---|
PriorityQueue | O(log n) | O(1) | O(log n) | O(1) |
ConcurrentLinkedQueue | O(1) | O(1) | O(1) | O(n) |
ArrayBlockingQueue | O(1) | O(1) | O(1) | O(1) |
LinkedBlockingQueue | O(1) | O(1) | O(1) | O(1) |
PriorityBlockingQueue | O(log n) | O(1) | O(log n) | O(1) |
DelayQueue | O(log n) | O(1) | O(log n) | O(1) |
LinkedList | O(1) | O(1) | O(1) | O(1) |
ArrayDeque | O(1) | O(1) | O(1) | O(1) |
LinkedBlockingDeque | O(1) | O(1) | O(1) | O(1) |
PriorityQueue, PriorityBlockingQueue and DelayQueue
A PriorityQueue is used when the priority of processing objects matters. You can use the natural order o supply a Comparator at queue construction time. A PriorityQueue is recommended to be used when you want to define a new ordering that only depends on priorities.
The PriorityQueue is based on the priority heap.
A Priority Heap is a binary tree with to requirements: each node in the tree should be larger than either of its children and all the level on the tree must be complete except the lowest.
This implementation does not support thread safety and its iterator is fail-fast. If concurrency is a must, you can use PriorityBlockingQueue instead.
A DelayQueue is a priority queue with an ordering based on the delay time for each element. The delay time is the time until the element is ready to be taken from the queue.
When none of the elements are ready to be taken it will return null. On the other hand, if there are multiple elements waiting for getting taken, the one waiting for longer will be at the head of the queue. This implementation has the performance characteristics of PriorityQueue and is thread-safe as PriorityBlockingQueue.
ConcurrentLinkedQueue
This Queue implementation uses a linked structure, so ConcurrentLinkedQueue is very good at insertion and removal operations at the end of the queue, so nodes do not need to be located using a sequential search.
ConcurrentLinkedQueue is thread-safe and uses a compare-and-swap (CAS) mechanism for insertion and removal.
CAS is an algorithm used in multithreading to achieve synchronization.
LinkedBloquingQueue
This implementation of BlockingQueue is also based on a linked structure, so it guarantees that the queue operations are thread-safe and atomic. Again, insertion and removal perform at constant time whereas search operations runs in linear time.
IMPORTANT:
Collectionoperations are not guaranteed to be thread-safe, unless the implementation provides it.
ArrayBlockingQueue
This is a circular array, which means the first and last elements are adjacent.
The size of ArrayBlockingQueue is defined when is created, so once is full it doesn’t allow you to add more elements.
This implementation is also thread-safe and you can configure it to have a fair scheduling policy, or to allow the class to choose which thread goes first.
Fair scheduling policy: The thread that has been waiting for longer is chosen.
Insertion and removal operations are executed in constant time, whereas search operations have to iterate over it.
SynchronousQueue
A SynchronousQueue only allows one element at a time in the queue, so each insert operation must wait for a thread to take the element of the queue. The same happens when an element wants to be taken, it has to wait until a thread puts an element.
This class is very convenient when you want to synchronize two threads running in different objects and one of them wants to pass some information to the other thread.
ArrayDeque
An ArrayDeque is a double ended queue, which means you can put element at both ends. This implementation of Deque interface is based on a circular array like ArrayBlockingQueue, so it has the same performance features of a circular array. Insertion and removal operations are executed in constant time, whereas search operations run in linear time and are fail-fast.
LinkedBlockingDeque
This implementation of BlockingDeque is built on top of a doubly linked list structure, and has similar performance features as LinkedBlockingQueue. Insertion and removal operations run in constant time, whereas search operations like contains, execute in linear time.
Map Interface
The Map interface does not inherit from Collection and it provides four groups of operations:
- Insertion:
putandputAll - Removals:
clearandremove - Search:
get,containsKey,containsValue,sizeandisEmpty - Sub collections:
entrySet,keySetandvalues
There are 8 implementations of the Map interface.

The time complexity of the operations is calculated with the Big O notation.
| name | get | containsKey | next | Notes |
|---|---|---|---|---|
HashMap | O(1) | O(1) | O(h/n) | h is the table capacity |
LinkedHashMap | O(1) | O(1) | O(1) | |
IdentityHashMap | O(1) | O(1) | O(h/n) | h is the table capacity |
EnumMap | O(1) | O(1) | O(1) | |
TreeMap | O(log n) | O(log n) | O(log n) | |
ConcurrentHashMap | O(1) | O(1) | O(h/n) | h is the table capacity |
ConcurrentSkipListMap | O(log n) | O(log n) | O(1) |
HashMap and LinkedHashMap
HashMap implementation has all the properties of a hash table and provides constant time performance on put and get operations if there is no collisions.
LinkedHashMap guarantees the insertion order by using internally a linked list for the keys. Additionally, this implementation provides a special constructor to switch the iteration order to a last access order in which its entries are ordered from least-recently accessed to most-recently.
WeakHashMap
A WeakHashMap is a Map implementation with weak keys. A weak key means that it will be ready for garbage collection once there are not strong references to it. Under the hood, WeakHashMap uses WeakReference for the keys, however the value objects are held by ordinary strong references.
This class can be ideal for caching or storing metadata about the object.
A strong reference is an ordinary Java reference, the kind you use every day e.g.
StringBuffer buffer = new StringBuffer();
A weak reference is a reference that is not strong enough to force an object to remain in memory. As a result, the weak reference isn’t strong enough to prevent garbage collection, so you may get a
nullvalue. They are useful to avoid memory leaks.
Performance is similar to HashMap.
IdentityHashMap
This is an implementation of Map that uses a hash table as the HashMap implementation, but in this case instead of comparing keys by object equality, it uses reanference-equality. This means two keys are the same if key1==key2, whereas in a standard HashMap two keys are the same if key1.equals(key2).
This implementation has the same performance as a HashMap.
EnumMap
EnumMap is an implementation specific for Enum type, so you can take advantage of the performance benefits from the enumerated type.
This implementation is not thread-safe.
NavigableMap
This class provides navigation methods to return the closest matches for given search targets.
TreeMap
TreeMap is an implementation of SortedMap and is based on a Red-Black tree. The map is sorted according to the natural ordering of its keys, or by a Comparator.
Red-Black tree is a self balanced tree in which each node stores an additional bit to store the color. Nodes of the tree are painted either with red or black and every time the tree is modified the nodes are rearranged and repainted.
The performance of TreeMap is the same as the TreeSet, O(log(N)).
ConcurrentHashMap
ConcurrentHashMap is an implementation of ConcurrentMap and provides thread safety. This class is optimize for retrieval, so reading operations do not block update operations. If an update operation is taking place while you are retrieving object, it will return the object with the state present when the retrieval operation started.
The performance of ConcurrentHashMap is similar to HashMap.
ConcurrentSkipListMap
This map establishes a sorting order according to the natural ordering of its keys and behaves in the same way as ConcurrentSkipListSet.
Search operations performance is O(log(N)), whereas iterative operations run in constant time.